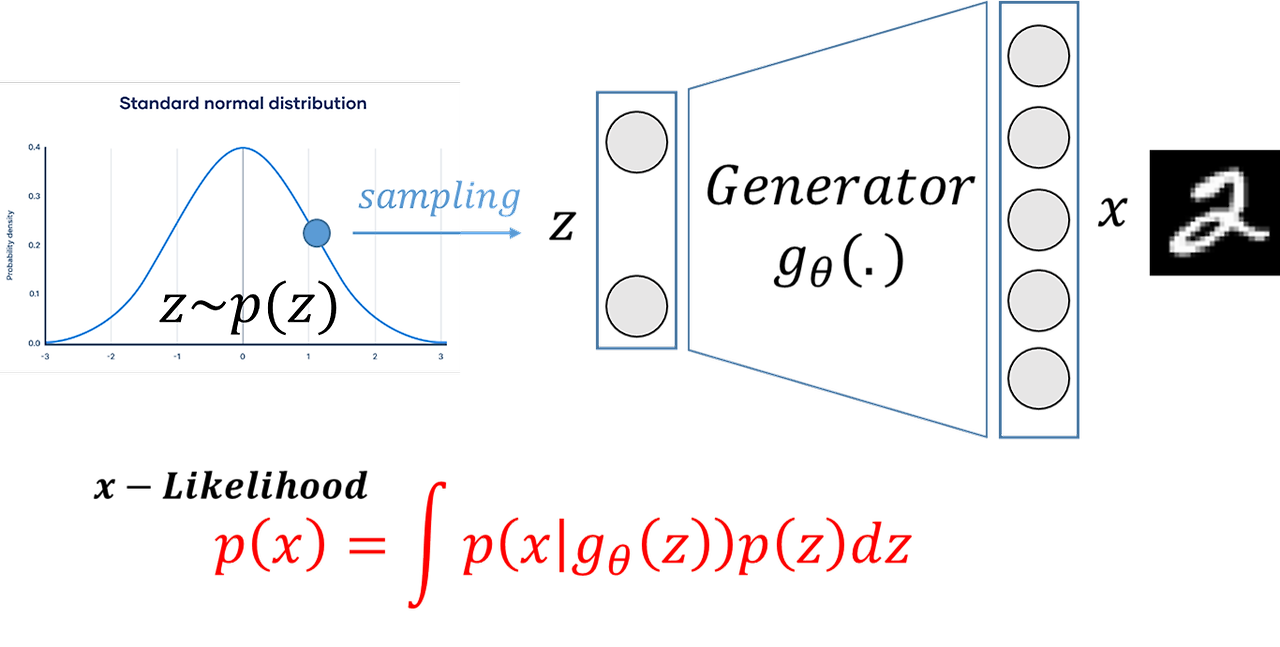
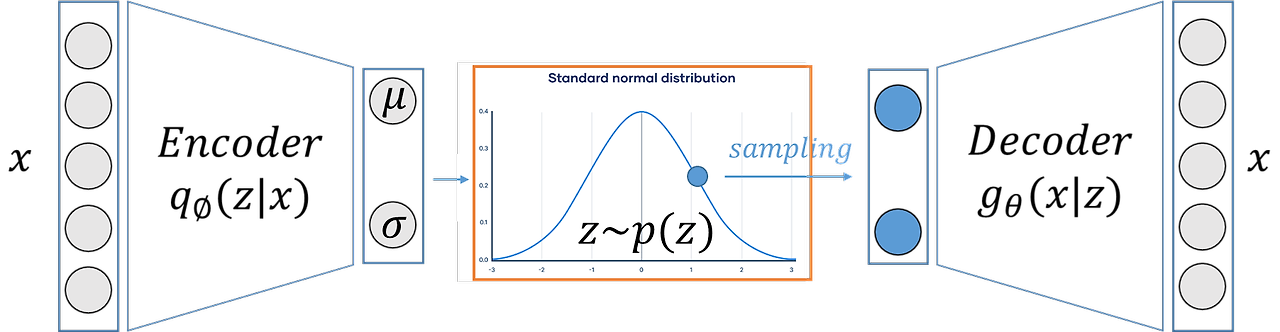
인코더를 사용해서 를 근사하는 가우시안 분포를 찾아주고, 거기서 샘플링해서 표본 와 유사하도록 생성하는 decoder를 학습한다.
Encoder에서 적어도 x에 대한 성능이 보장이 되는 최적의 샘플링 함수를 만들기 위해 와 를 추정하여 가우시안 함수를 구성합니다. 이 이미지 x에 대한 최소한의 성능은 보장하면서, 이미지를 잘 컨트롤하여 여러 이미지를 생성하기 위해 z를 샘플링합니다. 이제 이 z를 Decoder에 입력하여 다시 x 이미지를 생성합니다.
ELBO (Evidence Lower Bound)
여기서 는 인풋 를 넣었을 때, 그것과 유사한 것을 잘 생성해내는 함수이다.
이러한 함수와 가장 유사한 함수를 만드려고 하는데, 그 loss를 계산해보면 위와 같다.
중요한 점은, ELBO를 ML(Maximum Likelihood)에 가깝게 최대화 하면 KL Divergence가 자연스럽게 0으로 수렴하고, 이는 (VAE의 인코더)가 true posterior인 에 가까워 진다는 것이다!
나는 latent 보고 뭔가 잘 생성하는 생성 모델을 만들고 싶어.
근데 그냥 아무무 가우시안에서 생성하니 자기 자신도 생성을 잘 못하네.
그래서 아무무 가우시안이 아니라 자기 자신을 참고한 확률 분포 에서 샘플링한 다음에 생성하고 싶어.
그런데 는 그냥 못구해.
그래서 이것을 구하기 위해서 딥러닝 모델을 쓸거야.
그래서 인코더가 가우시안 분포를 사용해서 를 근사하고, 해당 근사된 분포에서 샘플링해서 디코더를 통과하면 원래 넣어준 인풋과 유사하게 생성하도록 훈련할거야.
이렇게 하니깐 오토인코더랑 어느정도 비슷하게 되었네??
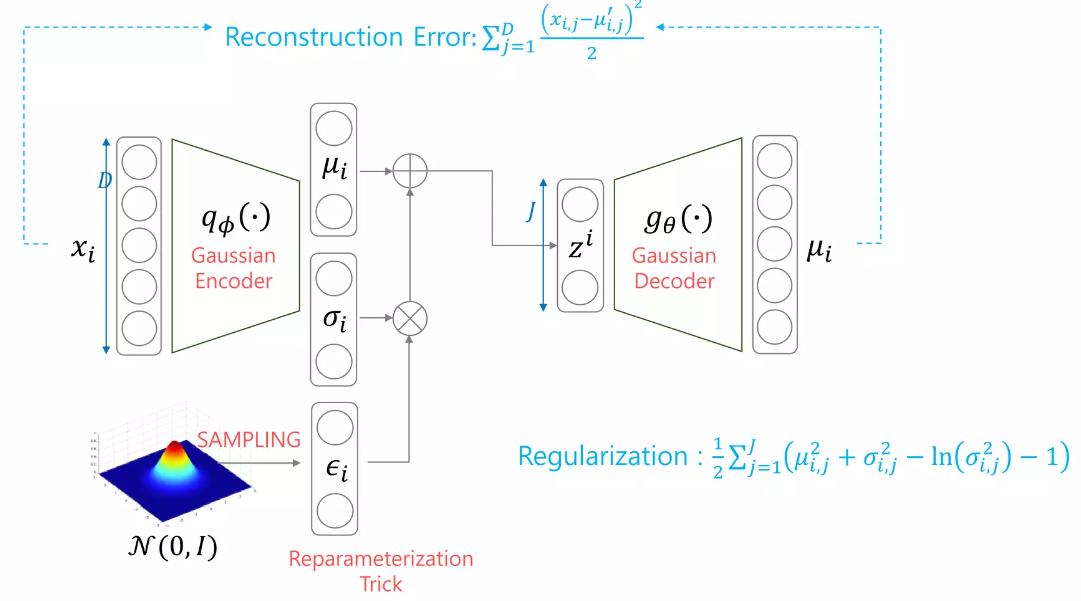
훈련을 위해서는 Reconstruction Error, 즉 원래 인풋과 비슷하게 생성이 되었는가?
Regularization Error, 인코더에서 나온 것들이 잘 정규화 되었는가?
이 두가지를 쓸거고, 학습을 위해 Reparameterization Trick을 사용할거다!